Azure autoscaling best practices: an addition
If you don't use a scale-out and scale-in rule combination, then you might get flapping.

One autoscaling best practice mentioned in the Microsoft Docs [archived Microsoft Docs link] is:
Always use a scale-out and scale-in rule combination that performs an increase and decrease
If you use only one part of the combination, autoscaling will only take action in a single direction (scale-out, or in) until it reaches the maximum, or minimum instance counts, as defined in the profile. This is not optimal, ideally you want your resource to scale up at times of high usage to ensure availability. Similarly, at times of low usage you want your resource to scale down, so you can realize cost savings.
What this paragraph doesn't say is that if you have a scale condition like:
Scale outWhen example-asp (Average) CpuPercentage > 90 Increase count by 1Or example-asp (Average) MemoryPercentage > 90 Increase count by 1Scale inWhen example-asp (Average) CpuPercentage < 45 Decrease count by 1
Then your example-asp might get stuck in a flapping state (the condition in which instances scale up and down rapidly and repetitively).
This is because the ASP might meet both the memory-based scale-out condition and the CPU-based scale-in condition.
The rest of the essay will tell the story of how I arrived at this discovery along with some insights so you can avoid spending one week with a Microsoft representative trying to diagnose the same behavior.
Work item
On the 17th of June, 2021, I picked up a task from the backlog which read:
Our App Service Plan is set to scale automatically, but that leads to some errors while the ASP is scaling: (it seems) mostly HTTP calls that call an instance which is starting or shutting down. Please investigate if it's better to disable autoscaling; and, if so, how many instances would we need?
The HTTP errors could have easily been caused by services hitting unhealthy instances because the apps in the ASP didn't have health checks. But, investigating the problem from the ticket led me to the core issue of this essay: Azure autoscaling is a black box service that you can use but not perfectly tune because you don't have all the information, only metrics, logs, correlations, and speculations.
With that in mind, I looked at the metrics of each individual app and of the ASP. In total, 6 apps had the pattern of a stable instance which got replaced by another stable instance; each instance lasted for about 4 days. All apps had ephemeral instances (i.e. with a 1-2 day lifespan); this was because of the sub-optimal scaling condition that had the scale-in threshold set at 60 and the scale-out at 80.
The average CPU utilization of the ASP was between 23% - 30% while the average memory usage was between 63% - 78%.
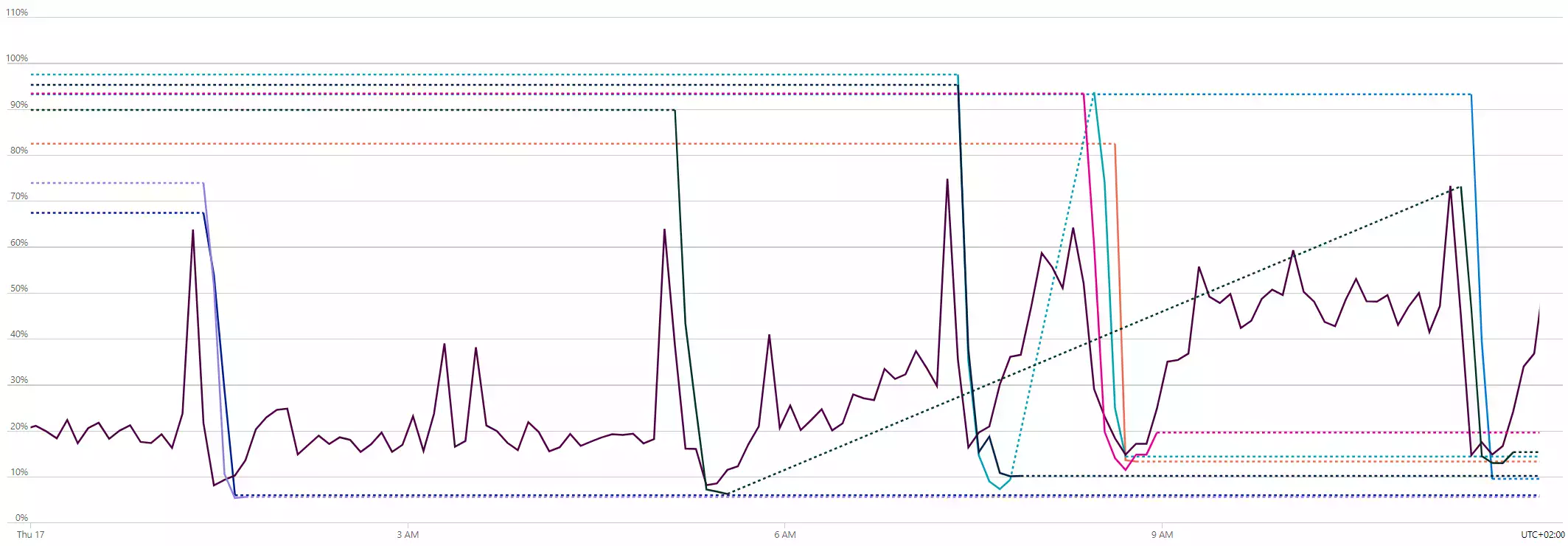
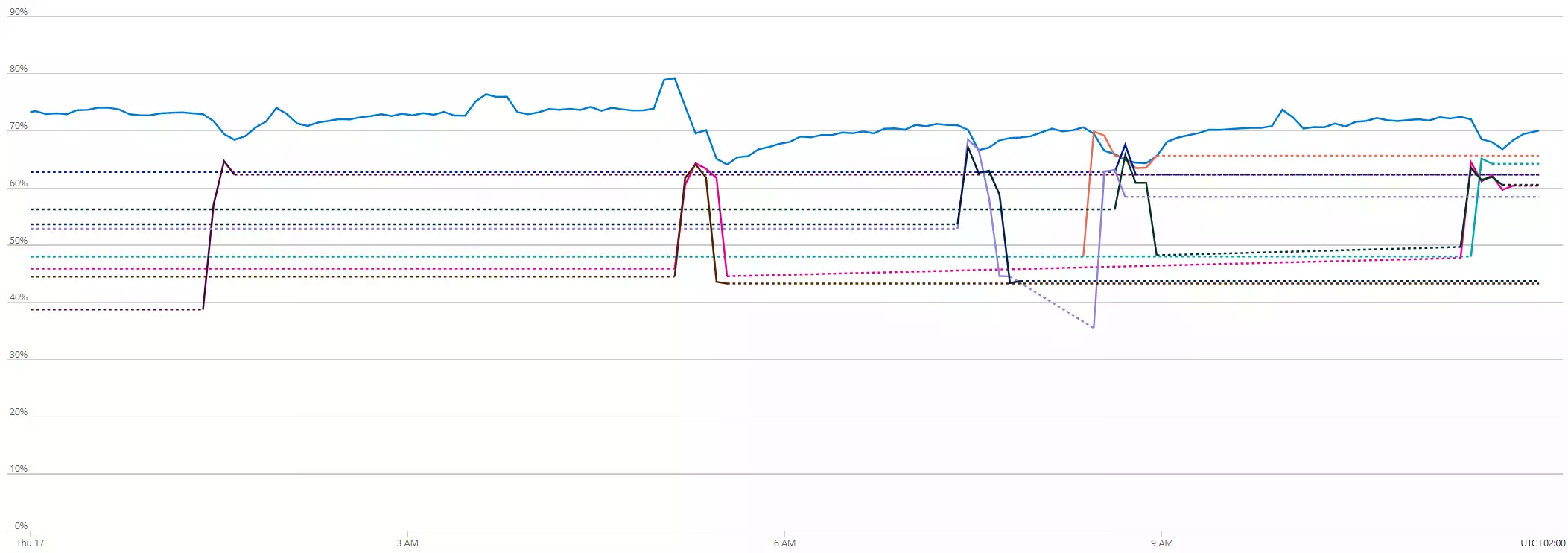
The scale condition was based on the CpuPercentage metric, which was fine, but the scale-in and scale-out thresholds were too close to each
other (only 20 percentage points) which led to flapping and, possibly, to the HTTP error calls.
After some tweaking, I arrived at the scale condition mentioned at the beginning of the essay (scale-in at 45 and scale-out at 90) which eliminated the HTTP errors but not the flapping. Flapping should have no longer occurred, but, instead, the ASP was stuck with 2 instances.
The autoscale engine determines when to scale-in based on this formula:
used scale-in metric value x current instance count / final number of instances when scaled down
The reasoning behind this equation is simple: if you have a workload that is divided across N instances that is to be moved to, for example, N - 1 instances, then the N - 1 instances should be able to handle the workload that was present on the N instances.
The official Microsoft documentation
[archived documentation] explains why the formula uses all metric types of a scaling condition's scale-in rules
when determining when to scale in: Autoscale only takes a scale-in action if all of the scale-in rules are triggered.
For the ASP in question, the formula should then be: 30 (average CPU usage) x 2 (current number of instances) / 1 (desired number of instances) = 60. This is 30% below the scale-out threshold I implemented, yet the ASP was stuck in endless flapping. This should only happen if the outcome of the equation is 90% or more.
After depleting the available information on the subject (i.e. the official docs, a StackOverflow post [archived version], and a blog post [archived version]) I decided to contact Microsoft.
Microsoft Support ticket
A Microsoft representative from the App Service team proposed two solutions:
- Switch the App Service Plan to the P1V2 tier: same costs but newer hardware with slightly more computing resources.
- Remove the
MemoryPercentagerule as it might interfere with the CPU one. Alternatively, add a scale-inMemoryPercentagerule, which I didn't do because memory usage was fluctuating more than CPU usage, thus making the task of setting memory scale-in and scale-out thresholds harder.
He also recommended lowering the scale-out threshold to CpuPercentage > 80 because that's what they usually recommend to their clients.
I chose to ignore his recommendation based on 2 facts:
- The way the CPU usage increases in the ASP (i.e. rare spikes that go from 30% straight to 90% - 95% in under 1 minute) makes it so that reducing the scale-out threshold by 10% would have no positive impact and one negative impact; that is...
- Lowering the scale-out threshold would require lowering the scale-in threshold too (for example, to 40%). This would result in 5% more inefficient use of computing resources because lowering the scale-in threshold increases the permissible amount of idling resources. This is not necessarily bad (say, if you have a workload that fluctuates), but it's not optimal for the ASP in question. I would have to lower the scale-in threshold because if I implement the recommended scale-out threshold of 80 but don't also lower the scale-in threshold to at least 40, then the ASP can never scale in to 1 instance. If the CPU usage is 44% (slightly below the current scale-in threshold) averaged across 2 instances, the Azure autoscaler would perform the following calculation: 44 x 2 / 1 = 88. The result is above the recommended scale-out threshold of 80. Thus, the autoscaler would produce a flapping event and refrain from scaling in because then it would have to scale out again immediately afterwards.
But don't bother with why I ignored his recommendation for now. This will come in useful at the end of the essay as context for the questions I still have unanswered. For now, let's focus on his solutions.
The first solution didn't eliminate the flapping but removing the MemoryPercentage rule did the trick. We have a winner:
Scale outWhen example-asp (Average) CpuPercentage > 90 Increase count by 1Scale inWhen example-asp (Average) CpuPercentage < 45 Decrease count by 1
The representative didn't explain why or how a scale-out rule might interfere with another scale-out rule, even after I pointed out that the
Or in the scale condition syntax makes it seem like the scale-out rules are not connected to each other.
Then my friend Yannis, who has no familiarity with Azure, gave what I think to be the right explanation: sometimes the ASP might get stuck in flapping because both a memory-based scale-out condition and a CPU-based scale-in condition are met at the same time.
This might be why if you set two scale-in conditions, one will be prefixed by When and the other by And, but if you set two
scale-out conditions, one will be prefixed by When and the other by Or:
Scale outWhen example-asp (Average) CpuPercentage > 90 Increase count by 1Or example-asp (Average) MemoryPercentage > 90 Increase count by 1Scale inWhen example-asp (Average) CpuPercentage < 45 Decrease count by 1And example-asp (Average) MemoryPercentage < 45 Decrease count by 1
Now the issue is closed:
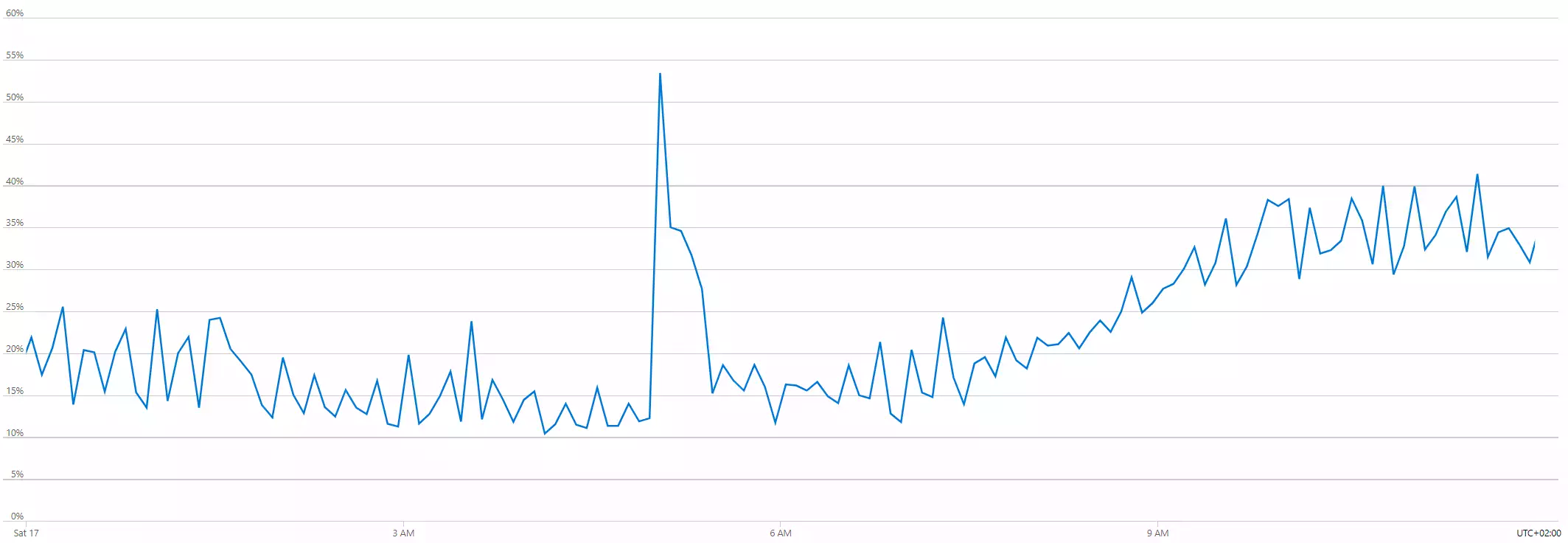
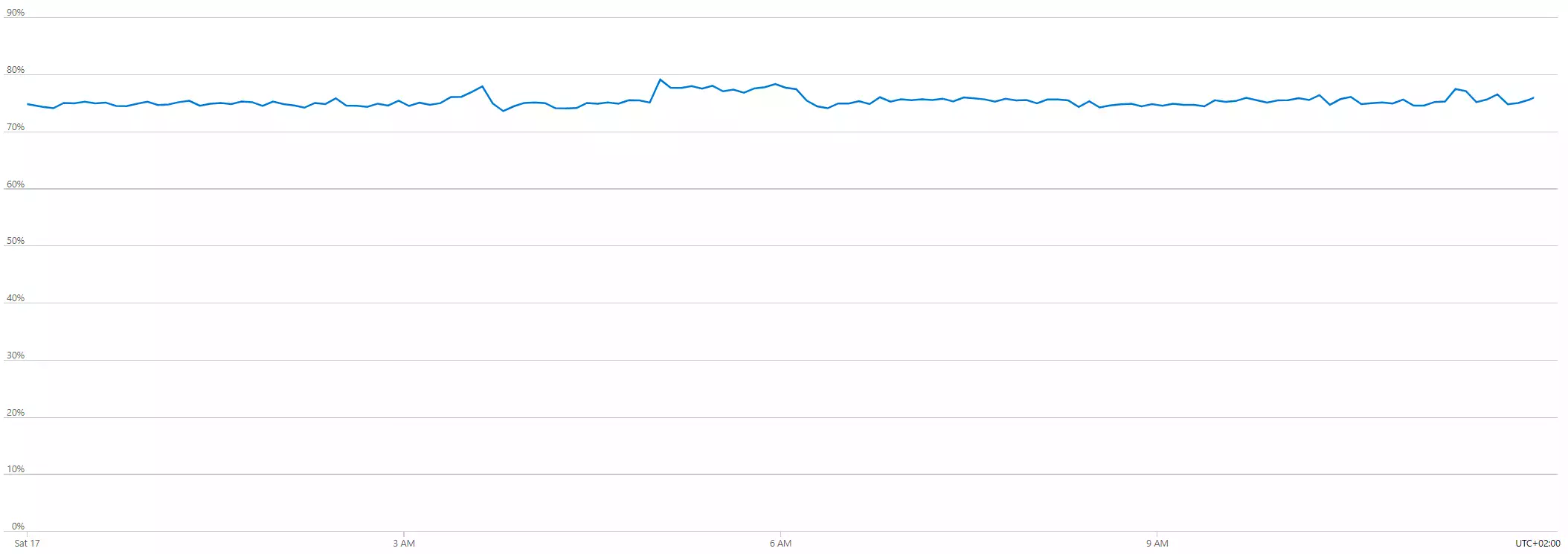
But still, all of this is speculation and the only reason I'm explaining myself at length is to give context for the questions I am still left with.
Questions
- How does the autoscale engine (a.k.a. the Azure Monitor autoscale) evaluate the scaling condition? I would love to see the algorithm.
- How often does the autoscale engine evaluate the scaling condition? Is it 5 minutes [archived version]?
- How does the autoscale engine resolve edge cases? For example, is it safe for me to keep scale-in and scale-out rules that leave no leeway for the
scale-in calculation (as described in the second fact above)? The
Ensure the maximum and minimum values are different and have an adequate margin between them [archived link]
[archived link] best practice does not answer this question, unfortunately.
In short: how does Azure autoscaling work, precisely?
❦